Extraction des tags de mon blog en ligne de commande
J’aimerais savoir quels sont les tags que j’ai le plus employé sur ce blog. Pour cela il va d’abord falloir les extraire, si possible dans un fichier csv.
Comment ? En Ruby ? En R ? Non non, en Bash, ça va être beaucoup plus drôle.
Petite étude de cas pour découvrir la puissance de la ligne de commande, ou pour rafraichir ses connaissances ;)
Si vous voulez reproduire l’analyse en même temps que moi, les articles sont ici.
Voyons à quoi ressemble le début d’un article au hasard avec head.
Octopress, le framework que j’utilise pour ce blog, appelle les tags des
categories. Mais c’est pareil.
$ head 2013-10-20-les-algorithmes-genetiques-demystifies-35.markdown
---
layout: post
title: "Les algorithmes génétiques démystifiés 35"
date: 2013-10-20 21:21
legacy: true
ts: [imagerie, algorithme génétique, javascript]
#...L’entête d’un article a toujours la même structure. Avec head *.markdown
j’affiche le début de tous les articles, les uns à la suite des autres.
Avec sed je peux extraire uniquement les lignes qui commencent par cat :
$ head *.markdown | sed -n '/^cat/p'
tags: [ ]
tags: [vim]
tags: [ruby, code propre, intermédiaire]
tags: [ruby, eigenclass, object, intermédiaire]
#...Gardons seulement les tableaux. cut -f1 découpe le premier champ, -d' '
indique que le séparateur de champ est l’espace, et --complement indique
qu’on veut conserver le complément. Autrement dit tout sauf la première
colonne.
$ head *.markdown | sed -n '/^cat/p' |
> cut -f1 -d' ' --complement
[annonce, défi]
[vim, conseil, débutant]
[ruby, code propre, intermédiaire]
[ruby, eigenclass, object, intermédiaire]
#...Supprimons les crochets à l’aide de sed et d’une regex rigolote.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g'
annonce, défi
vim, conseil, débutant
ruby, code propre, intermédiaire
ruby, eigenclass, object, intermédiaire
#...Supprimons les espaces inutiles. Attention, certains tags contiennent des espaces.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' |
> sed 's/, /,/g'
annonce,défi
vim,conseil,débutant
ruby,code propre,intermédiaire
ruby,eigenclass,object,intermédiaire
#...Grâce à tr, je remplace chaque virgule par un retour à la ligne. Ça
commence à prendre forme.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' |
> tr ',' '\n'
annonce
défi
vim
conseil
débutant
ruby
code propre
intermédiaire
ruby
eigenclass
#...Trions par ordre alphabétique.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' |
> sort
ack
activerecord
activerecord
ag
airline
airline
airline
airline
algorithme génétique
#...Réduisons les occurrences et comptons les avec uniq -c.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' | sort |
> uniq -c
1
1 ack
2 activerecord
1 ag
4 airline
70 algorithme génétique
1 alias
16 annonce
3 app
1 application
#...Trions à nouveau, cette fois sur le nombre et du plus grand au plus petit.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' | sort | uniq -c |
> sort -nr
213 ruby
176 intermédiaire
171 débutant
70 algorithme génétique
55 vim
26 tutoriel
26 julia
26 javascript
#...
1 application
1 alias
1 ag
1 ack
1 Vous avez remarquez ? Un tag est vide. Ça pourrait poser problème pour la
suite. Avec sed on peut facilement supprimer la dernière ligne.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' | sort | uniq -c |
> sort -nr | sed '$d'
213 ruby
176 intermédiaire
171 débutant
#...
1 alias
1 ag
1 ackÀ la réflexion je préfère faire comme si il y avait plusieurs lignes vides et les supprimer toutes. Ça pourrait être plus réutilisable.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' |
> sed '/^$/d' |
> sort | uniq -c | sort -nrIl est temps de sortir une regex un peu plus complexe pour inverser les deux champs et ajouter une virgule entre eux.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' | sed '/^$/d' |
> sort | uniq -c | sort -nr |
> sed -r 's/\s+([0-9]+) (.*)/\2,\1/'
ruby,213
intermédiaire,176
débutant,171
algorithme génétique,70
#...C’est quasiment terminé. Il reste à ajouter l’entête du fichier csv. Pour cela
je vais utiliser une commande non standard mais bien pratique, header.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' | sed '/^$/d' |
> sort | uniq -c | sort -nr | sed -r 's/\s+([0-9]+) (.*)/\2,\1/' |
> header -a tag,frequency
tag,frequency
ruby,213
intermédiaire,176
débutant,171
algorithme génétique,70
#...On a terminé. C’est un beau pipeline, non ? Enregistrons le résultat dans un fichier.
$ head *.markdown | sed -n '/^cat/p' | cut -f1 -d' ' --complement |
> sed 's/[][]//g' | sed 's/, /,/g' | tr ',' '\n' | sed '/^$/d' |
> sort | uniq -c | sort -nr | sed -r 's/\s+([0-9]+) (.*)/\2,\1/' |
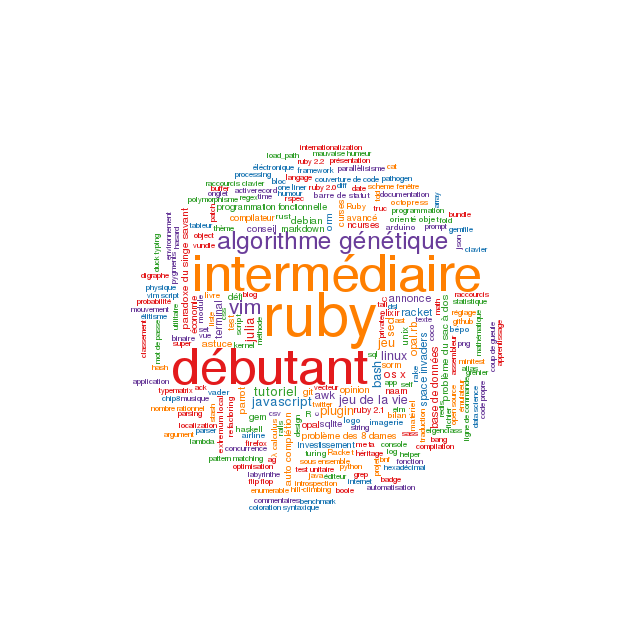
> header -a tag,frequency > tags.csvEn bonus, voici le code R qui produit l’image qui illustre cet article.
library(wordcloud)
d <- read.csv('tags.csv')
colors <- brewer.pal(12, 'Paired')
colors <- colors[seq(2, 10, by=2)]
wordcloud(d$tag, d$frequency, colors=colors, min.freq=1, scale=c(5, .6),
rot.per=.25, random.order=FALSE, random.color=TRUE)